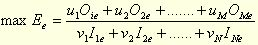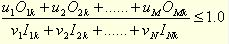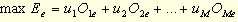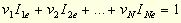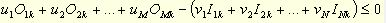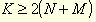数学建模算法汇总
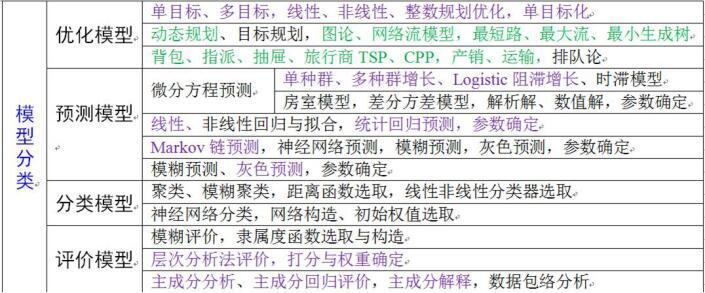
优化模型
优化模型(1)
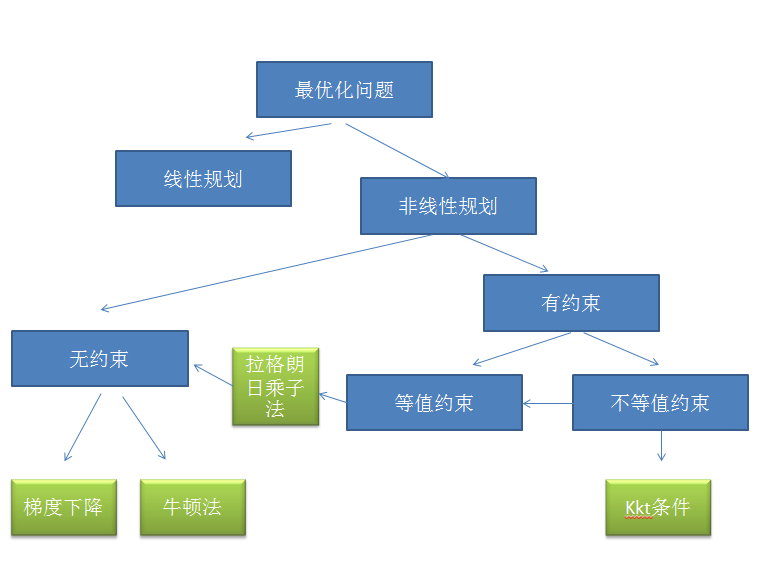
三要素: 决策变量、目标函数、约束
https://blog.csdn.net/luolang_103/article/details/80567443
单目标(Single-Objective Optimization Problem)
所评测目标只有一个,只需要根据具体的满足函数条件,求得最值
多目标(Multi-objective Optimization Problem)
多目标优化问题中,同时存在多个最大化或是最小化的目标函数,并且,这些目标函数并不是相互独立的,也不是相互和谐融洽的,他们之间会存在或多或少的冲突,使得不能同时满足所有的目标函数。
线性
线性规划问题是要最小化或最大化一个受限于一组有限的线性约束的线性函数
https://blog.csdn.net/fjssharpsword/article/details/53195556
非线性
如果目标函数或者约束条件中至少有一个是非线性函数时,最优化问题叫做非线性规划问题
https://blog.csdn.net/qjzcy/article/details/51727741
整数规划优化
全部变量限制为整数的规划问题,称为纯整数规划;部分变量限制为整数的规划问题,称为混合整数规划;变量只取0或1的规划问题,称为0-1整数规划。
整数规划问题,建议使用Lingo软件求解。常用的整数规划问题解法有:
(1)分枝定界法:可求纯或混合整数线性规划。
(2)割平面法:可求纯或混合整数线性规划。
(3)隐枚举法:用于求解0-1整数规划,有过滤法和分枝法。
(4)匈牙利法:解决指派问题(0-1规划特殊情形)。
(5)蒙特卡罗法:求解各种类型规划。
https://zhuanlan.zhihu.com/p/27976866
单目标化
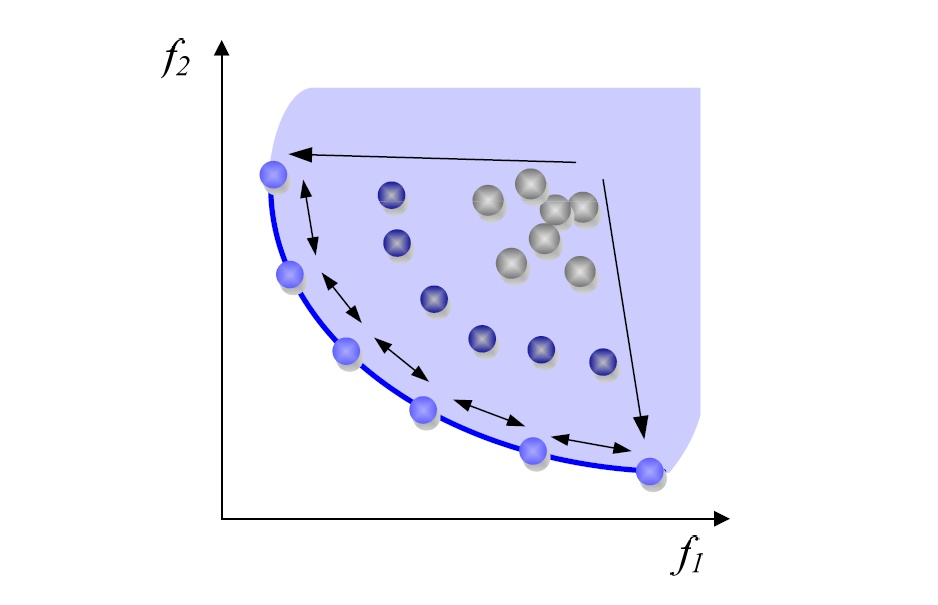
一般采用两个目标函数加权相加的形式。加权可以解决两个目标函数量纲不一致,或者变化剧烈程度不一致的问题,不过权重本身需要人为选取。
一般不使用乘法来组合目标函数,因为这样会使得导数的形式变得复杂。
https://zhuanlan.zhihu.com/p/30383993
优化模型(2)
动态规划 Dynamic Programming

1 | A * "1+1+1+1+1+1+1+1 =?" * |
https://blog.csdn.net/u013309870/article/details/75193592
1. 将原问题分解为子问题
把原问题分解为若干个子问题,子问题和原问题形式相同或类似,只不过规模变小了。子问题都解决,原问题即解决(数字三角形例)。
子问题的解一旦求出就会被保存,所以每个子问题只需求 解一次。
2. 确定状态
在用动态规划解题时,我们往往将和子问题相关的各个变量的一组取值,称之为一个“状 态”。一个“状态”对应于一个或多个子问题, 所谓某个“状态”下的“值”,就是这个“状 态”所对应的子问题的解。
所有“状态”的集合,构成问题的“状态空间”。“状态空间”的大小,与用动态规划解决问题的时间复杂度直接相关。 在数字三角形的例子里,一共有N×(N+1)/2个数字,所以这个问题的状态空间里一共就有N×(N+1)/2个状态。
整个问题的时间复杂度是状态数目乘以计算每个状态所需时间。在数字三角形里每个“状态”只需要经过一次,且在每个状态上作计算所花的时间都是和N无关的常数。
3.确定一些初始状态(边界状态)的值
以“数字三角形”为例,初始状态就是底边数字,值就是底边数字值。
4. 确定状态转移方程
定义出什么是“状态”,以及在该“状态”下的“值”后,就要找出不同的状态之间如何迁移――即如何从一个或多个“值”已知的 “状态”,求出另一个“状态”的“值”(递推型)。状态的迁移可以用递推公式表示,此递推公式也可被称作“状态转移方程”。
数字三角形的状态转移方程:

https://blog.csdn.net/baidu_28312631/article/details/47418773
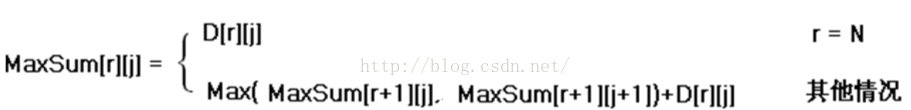
目标规划
1、加权系数法
为每一个目标加一个权系数,把多目标模型转化成单一目标模型。但是困难时确定合理的权系数,以反映不同目标之间的重要程度。
2、优先等级法
将各目标按其重要程度分为不同的优先等级,转化为单目标模型。
3、有效解法
寻求能够照顾到各个目标,并使决策者感到满意的解。由决策者来确定选取哪一个解,即得到满意的解。但是有效解太多,无法挑选
https://www.cnblogs.com/BlueMountain-HaggenDazs/p/4273802.html
图论
网络流模型
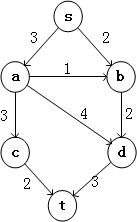
对于一个网络流我们可以用一个有向图G = (V,E,C)表示;V表示顶点的集合,E表示有向边的集合,C表示有向边的最大流量。对于每一个网络,有一个源输入点,称之为source,一个输出点,称之为sink。在不是出发点source也不是输出点sink的其他点,流量不能超过有向边的最大流量,这是一个约束条件。
下图就是一个简单的网络流模型:
https://blog.csdn.net/changyuanchn/article/details/17097807
最短路
最短路径问题
画图在线平台:
https://csacademy.com/app/graph_editor/
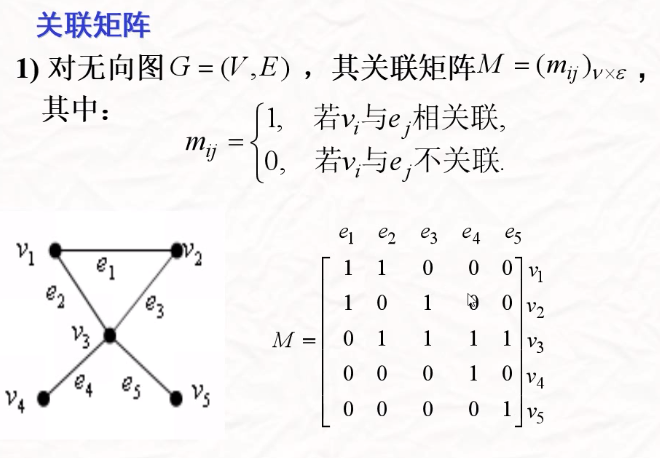
注意邻接矩阵和关联矩阵的概念!
邻接矩阵:元素为权值,不连接时为无穷(无权时为0/1表示是否相连)
解决方法:Dijkstra算法 Floyd算法
https://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html
https://blog.csdn.net/weixin_43791406/article/details/89314614

最大流
网络流图是一张只有一个源点和汇点的有向图,而最大流就是求源点到汇点间的最大水流量,下图的问题就是一个最基本,经典的最大流问题
流量,容量,可行流,增广路
https://blog.csdn.net/stevensonson/article/details/79177530
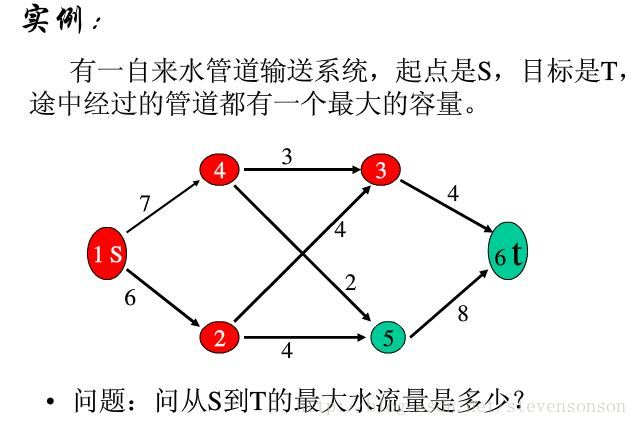
图就是一种管道,管道有最大通过流量的限制,图中边的权值就是所谓的“容量”。同时,注意有唯一的源点和汇点。
算法的关键在于
1)何为增广路径,如何找出增广路径。
2)如何更新流量
所谓增广路径,就是找到这样一条路径,其流量不满,未达到容量上限。
所有的可能的增广路径在一起便构成了残留网络
第一步,计算可增加流量
设某一增广路径上的节点为(a1,a2,a3,a4,…,an)
如果(u,v)是正向边,则增加流量d = min{ c(ai,aj) - f(ai,aj) | j = i +1, i =1,2,3…,n-1}
如果是逆向边,则增加流量d = min{ f(ai, aj) | j = i +1, i =1,2,3…,n-1}
第二步,更新流量
如果(u,v)是正向边,则 f(u,v) = f(u,v) + d
是逆向边,则f(u,v) = f(u,v) - d
注意,如果是逆向边,就是减法,当前管道从中减去部分流量,而且,伴随着这部分减去的流量,必有另一部分管道的流量会增加。。而且,最后的总流量增加了d
来自 https://www.cnblogs.com/ShaneZhang/p/3755479.html
最小生成树
图G=(V(G),E(G))树T=(V(T),E’(T))
在一个连通无向图G=(V, E)中,对于其中的每条边(u,v)∈E,赋予其权重w(u, v),则最小生成树问题就是要在G中找到一个连通图G中所有顶点的无环子集T⊆E,使得这个子集中所有边的权重之和最小。
即生成树为一条连接所有点的路径,最小生成树为权重和最小那个生成树(非环)
解决最小生成树问题有两个算法:Prim算法和Kruskal算法
Prim算法基本思想是从选点开始,再选择和不连通点之间的边,进而循环,每一次循环中,一个关键在于判断点之间是否不连通(对连通点集团进行编号,即只需判断集团编号是否相等即可),另一个在于选择最小的边。
Kruskal算法基本思想是从选最小边开始,连通成一个集团,进行编号,再选择不连通的集团的最小赋权边进行连接,依次循环。
https://blog.csdn.net/luoshixian099/article/details/51908175

优化模型(3)
背包
《背包问题九讲》
背包问题不单单是一个简单的算法问题,它本质上代表了一大类问题,这类问题实际上是01线性规划问题,其约束条件和目标函数如下:
eg:01背包问题,完全背包问题,多重背包问题,二维费用背包问题
http://dongxicheng.org/structure/knapsack-problems/
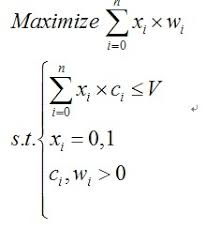
指派(分配问题)
实际中,会遇到这样的问题,有n项不同的任务,需要n个人分别完成其中的1项,每个人完成任务的时间不一样。于是就有一个问题,如何分配任务使得花费时间最少。
通俗来讲,就是n*n矩阵中,选取n个元素,每行每列各有1个元素,使得和最小。
如下图:
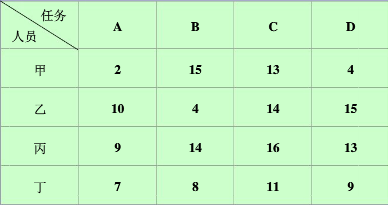
指派问题的最优解有这样一个性质,若从矩阵的一行(列)各元素中分别减去该行(列)的最小元素,得到归约矩阵,其最优解和原矩阵的最优解相同
匈牙利法:
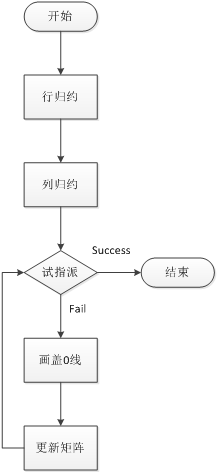
抽屉
旅行社TSP
Travelling Salesman Problem (TSP) 是最基本的路线问题。它寻求的是旅行者由起点出发,通过所有给定的需求点后,再次返回起点所花费的最小路径成本
整理模拟退火算法的程序!
http://blog.csdn.net/zhangzhengyi03539/article/details/46673545
https://www.cnblogs.com/ranjiewen/p/6815333.html
CPP
中国邮路问题,就是派邮递员送信,最后返回邮局,要求必须经过负责投递的街道至少一次,并且途径距离最短,属于图论里的euler回路
介绍:https://blog.csdn.net/gxuan/article/details/7869119
编程实现:https://www.cnblogs.com/guocai/archive/2012/07/08/2581979.html
产销
解决如何实现成本最小,利润最大的问题,问题的核心为如何求成本函数最小值的问题。
https://www.cnblogs.com/guocai/archive/2012/07/08/2581979.html
运输
四要素: 生产地,销售地,运输物资,运输价格
https://zhuanlan.zhihu.com/p/33299659

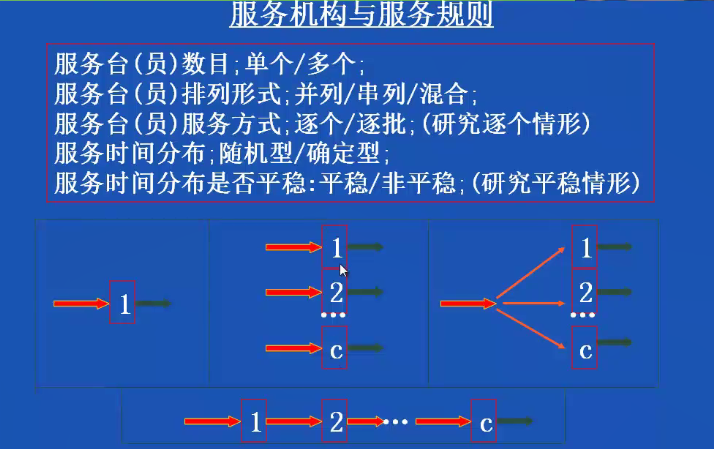
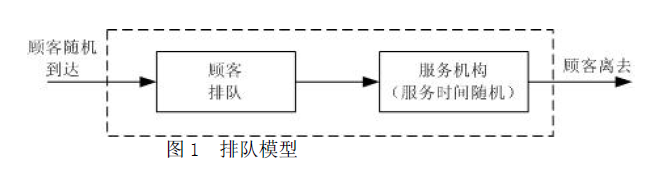
排队论
排队系统由三部分组成:
(1)顾客输入过程
(2)排队结构与排队规则
(3)服务机构与服务规则
一般研究的问题为总体为无限的,到达方式逐个,到达间隔随机,顾客之间相互独立,输入过程平稳。


https://www.cnblogs.com/BlueMountain-HaggenDazs/p/4270875.html
预测模型
预测模型(1)微分方程预测
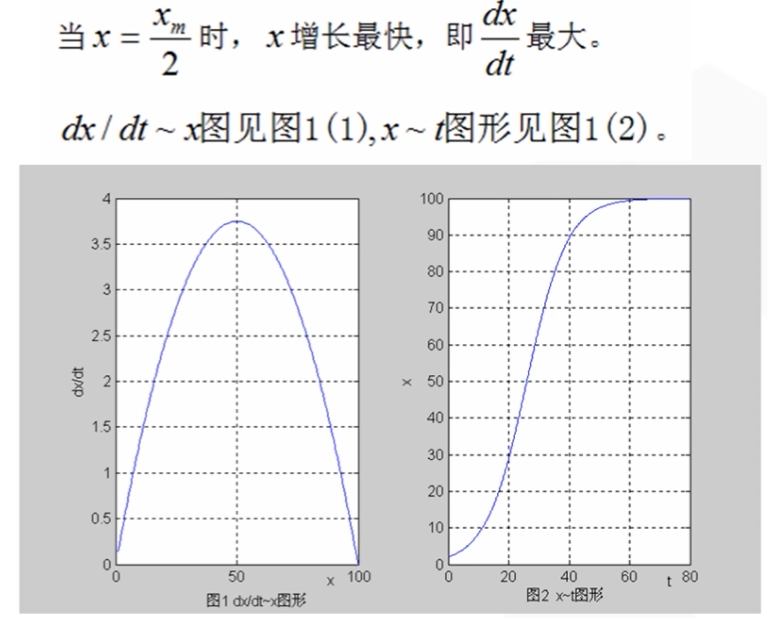
单种群

多种群增长


Logistic阻滞增长
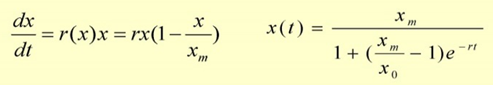
指数模型人口预测程序:
logistic阻滞型人口模型代码:
主要为nlinfit函数的使用



时滞模型
考虑到种群密度对种群增长的时滞作用而改进的一个种群连续增长模型。
预测模型(2)微分方程预测
房室模型
差分方差模型

解析解
解析解(analytical solution)就是一些严格的公式,给出任意的自变量就可以求出其因变量,也就是问题的解, 他人可以利用这些公式计算各自的问题.
数值解
解析解(analytical solution)就是一些严格的公式,给出任意的自变量就可以求出其因变量,也就是问题的解, 他人可以利用这些公式计算各自的问题.
参数确定
预测模型(3)
线性
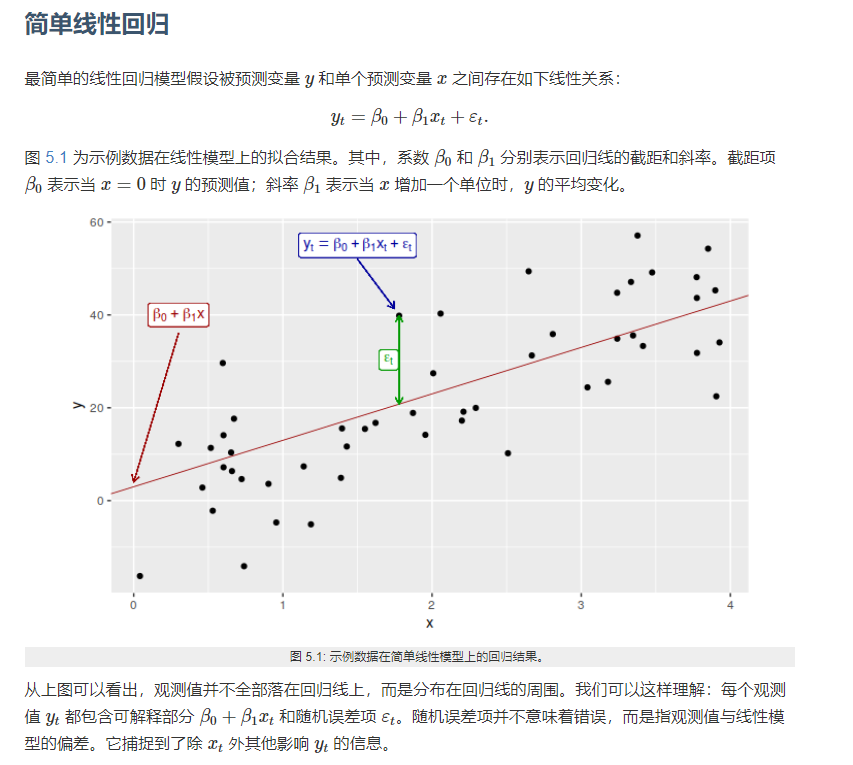
非线性回归与拟合
逻辑回归


统计回归预测
https://otexts.com/fppcn/forecasting-regression.html
https://blog.csdn.net/Android_xue/article/details/97614045

参数确定
预测模型(4)
Markov链预测
1.状态 在马尔可夫预测中,“状态”是一个重要的术语。所谓状态,就是指某一事件在某个时刻(或时期)出现的某种结果。一般而言,随着所研究的事件及其预测的目标不同,状态可以有不同的划分方式。譬如,在商品销售预测中,有“畅销”、“一般”、“滞销”等状态;在农业收成预测中,有“丰收”、“平收”、“欠收”等状态;在人口构成预测中,有“婴儿”、“儿童”、“少年”、“青年”、“中年”、“老年”等状态;等等。
2.状态转移过程 在事件的发展过程中,从一种状态转变为另一种状态,就称为状态转移。事件的发展,随着时间的变化而变化所作的状态转移,或者说状态转移与时间的关系,就称为状态转移过程,简称过程。
https://blog.csdn.net/qq_41686130/article/details/81906527
https://blog.csdn.net/bitcarmanlee/article/details/82819860
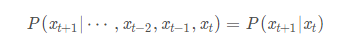

神经网络预测
https://otexts.com/fppcn/nnetar.html
https://blog.csdn.net/asd20172016/article/details/81454009
https://www.cnblogs.com/BlueMountain-HaggenDazs/p/4270391.html
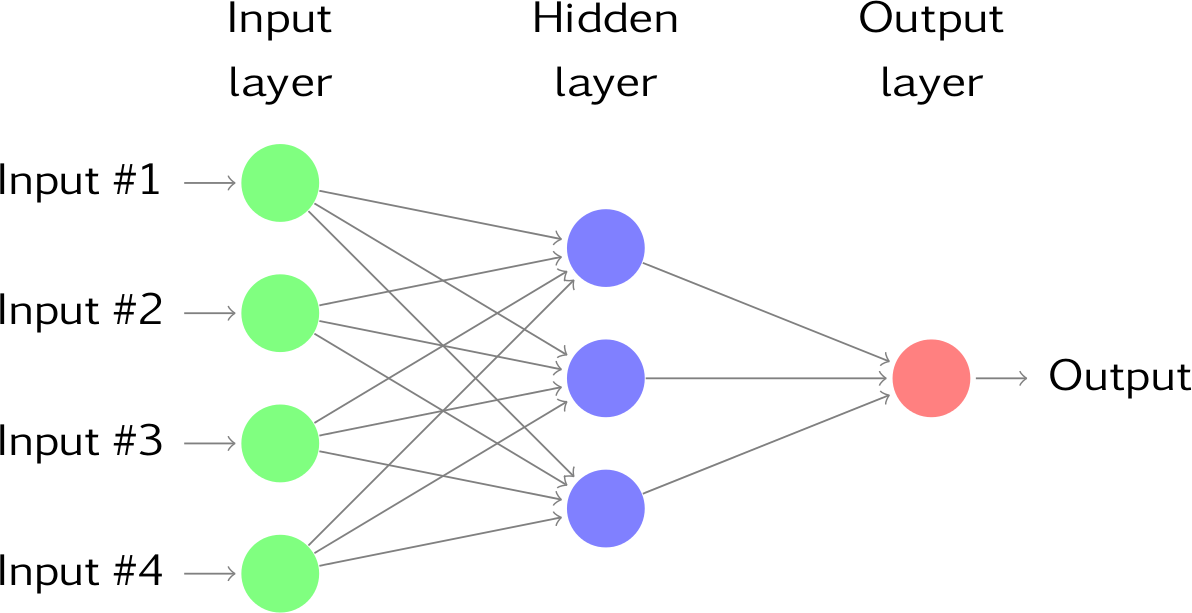
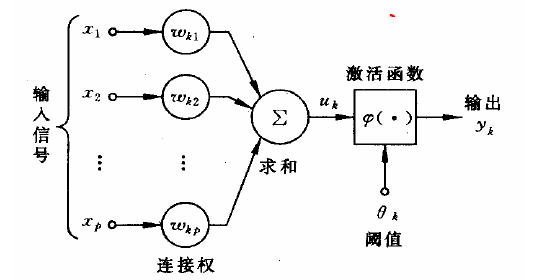
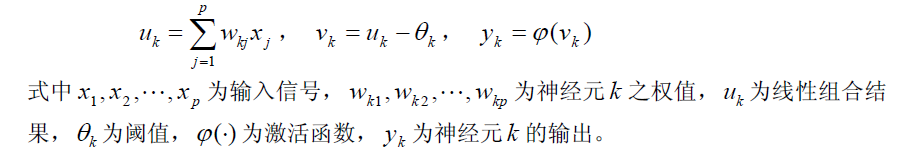
预测模型(5)
模糊预测
灰色预测
灰色系统介于白色和黑色之间,灰色系统内的一部分信息是已知的,另一部分信息是未知的,系统内各因素间有不确定的关系。
灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
数据生成:累加生成、累减生成、加权累加生成
灰色模型GM(1,1)
https://blog.csdn.net/qq547276542/article/details/77865341
参数确定
分类模型
分类模型(1)
https://blog.csdn.net/sinat_26917383/article/details/51611519
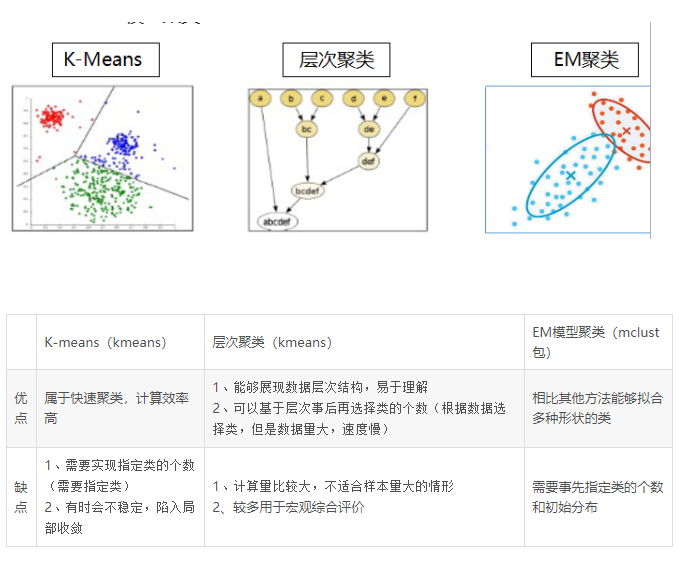
聚类
三类比较常见的聚类模型,K-mean聚类、层次(系统)聚类、最大期望EM算法
聚类分析的目的就是让类群内观测的距离最近,同时不同群体之间的距离最大。
K-mean聚类
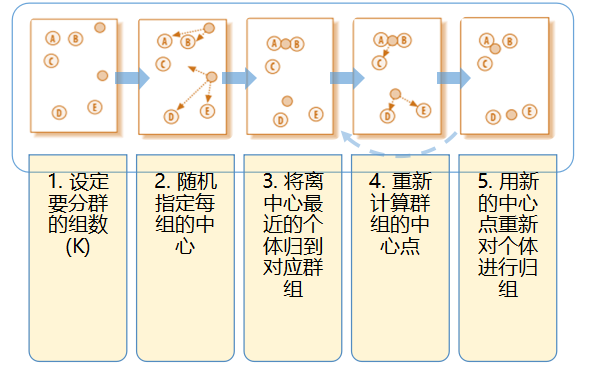
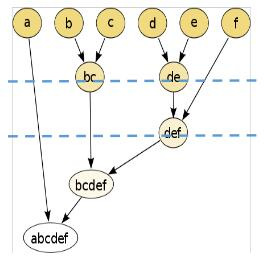
层次(系统)聚类
层次聚类也称系统聚类法,是根据个体间距离将个体向上两两聚合,再将聚合的小群体两两聚合一直到聚为一个整体。计算所有个体之间的距离,最相近距离的个体合体,不断合体。
最大期望EM算法
最大期望(EM)算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。
模糊聚类(FCM)
https://blog.csdn.net/WWWQ2386466490/article/details/80349239
隶属度
隶属度函数是表示一个对象x 隶属于集合A 的程度的函数,通常记做μA(x),其自变量范围是所有可能属于集合A 的对象(即集合A 所在空间中的所有点),取值范围是[0,1],即0<=μA(x),μA(x)<=1。μA(x)=1 表示x 完全隶属于集合A,相当于传统集合概念上的x∈A。
模糊集合
个定义在空间X={x}上的隶属度函数就定义了一个模糊集合A,或者叫定义在论域X={x}上的模糊子集A’。对于有限个对象x1,x2,……,xn 模糊集合A’可以表示为:
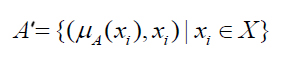
FCM聚类算法
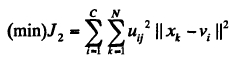
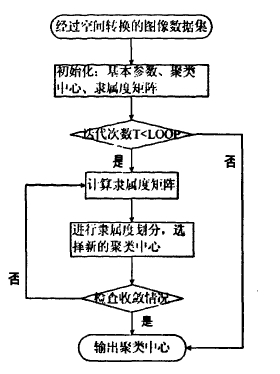
距离函数选取
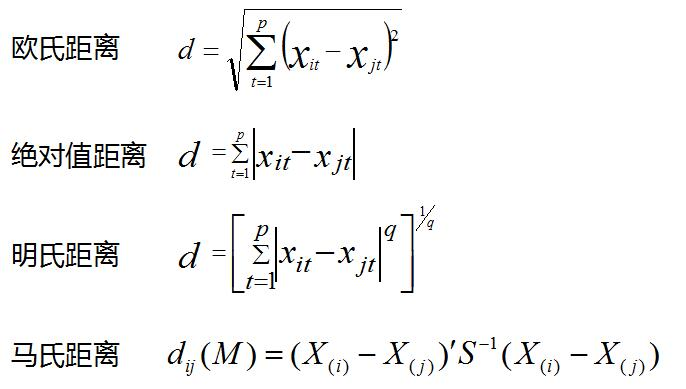
线性非线性分类器选取
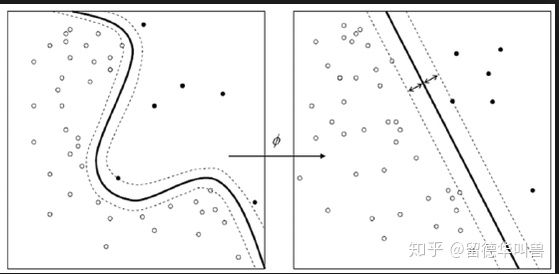
左边:非线性分类器
右边:线性分类器(又名:一刀切)
分类器
可以把输入数据分类的“东西”
https://www.zhihu.com/question/30633734/answer/463900106
分类模型(2)
神经网络分类
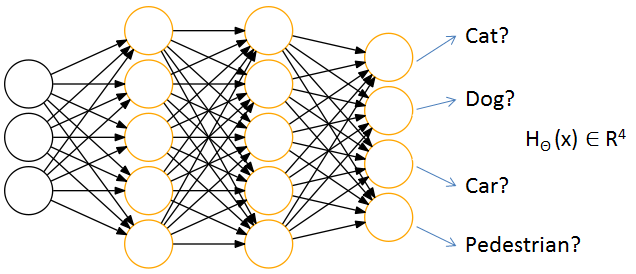
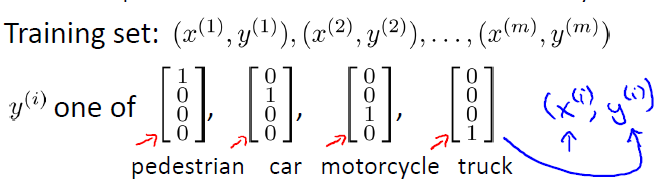
https://blog.csdn.net/HerosOfEarth/article/details/52165133
网络构造
A、输入量的选择:
a、输入量必须选择那些对输出影响大且能够检测或提取的变量;
b、各输入量之间互不相关或相关性很小。从输入、输出量性质分类来看,可以分为两类:数值变量和语言变量。数值变量又分为连续变量或离散变量。如常见的温度,压力,电压,电流等就是连续变量;语言变量是用自然语言表示的概念。如红,绿,蓝;男,女;大,中,小,开,关,亮,暗等。一般来说,语言变量在网络处理时,需要转化为离散变量。
c、输入量的表示与提取:多数情况下,直接送给神经网络的输入量无法直接得到,常常需要用信号处理与特征提取技术从原始数据中提取能反映其特征的若干参数作为网络输入。
B、输出量选择与表示:
a、输出量一般代表系统要实现的功能目标,如分类问题的类别归属等;
b、输出量表示可以是数值也可是语言变量;
https://blog.csdn.net/m0_37102093/article/details/78030711
初始权值选取
网络权值的初始化决定了网络的训练从误差曲面的哪一点开始,因此初始化方法对缩短网络的训练时间至关重要。
神经元的作用函数是关于坐标点对称的,若每个节点的净输入均在零点附近,则输出均出在作用函数的中点,这个位置不仅远离作用函数的饱和区,而且是其变化最灵敏的区域,必使网络学习加快。从神经网络净输入表达式来看,为了使各节点的初始净输入在零点附近,如下两种方法被常常使用:
A、取足够小的初始权值;
B、使初始值为+1和-1的权值数相等。
评价模型
评价模型(1)
模糊分析
1.建立综合评价的因素集
2.建立综合评价的评价集
3.进行单元素模糊评价,获得评价矩阵
4.确定因素权向量
5.建立综合评价模型
6.确定系统总得分
https://zhuanlan.zhihu.com/p/32666445


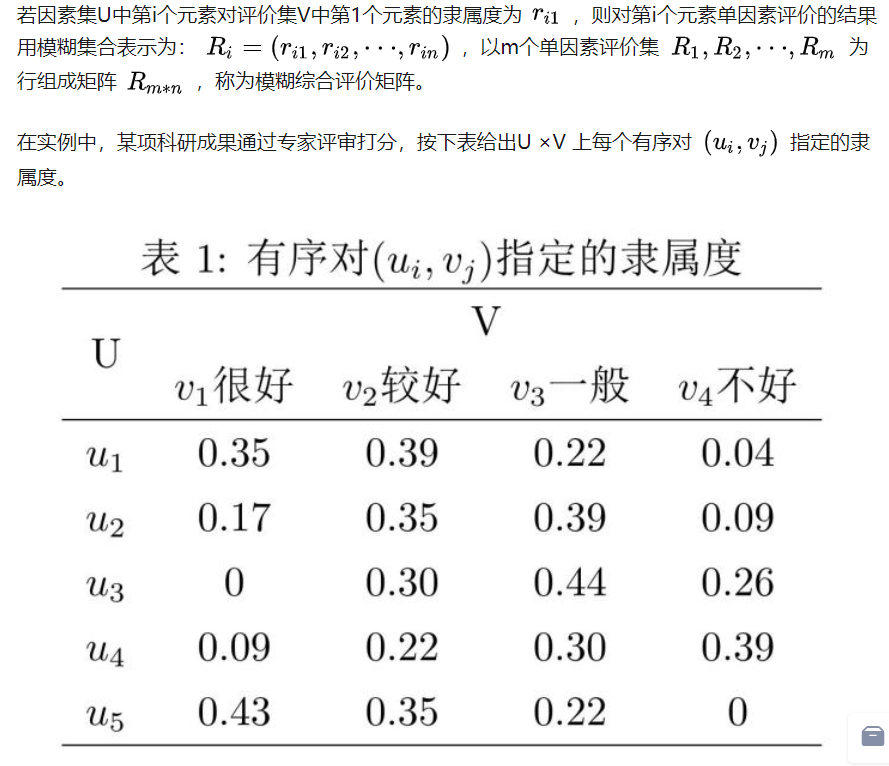


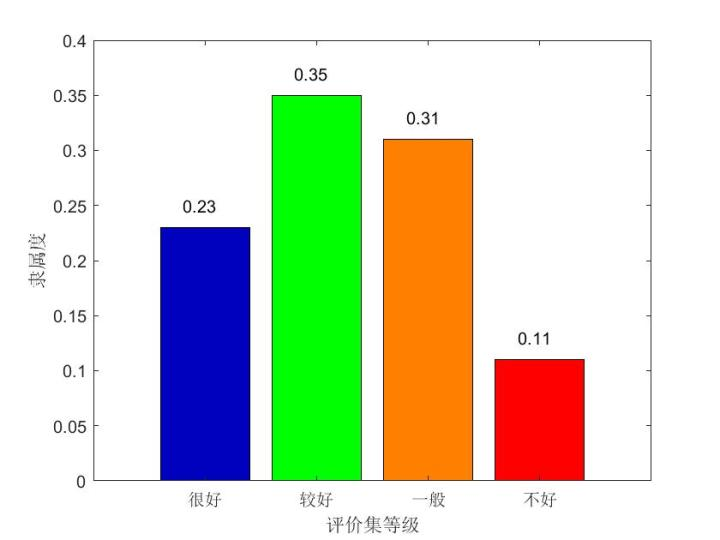

隶属度函数选取与构造
常用的方法:直觉方法,二元对比排序法,模糊统计试验法,最小模糊度法(根据先验知识和采集的数据,确定出描述模糊概念的候选隶属函数,利用最小化模糊度的原则计算相关的参数,进而获得合适的隶属函数)。
下面介绍三种最常用的隶属度函数:三角形隶属度函数、梯形隶属度函数、高斯型隶属度函数:
三角形隶属度函数
梯形隶属度函数
高斯型隶属度函数
https://zhuanlan.zhihu.com/p/37616833
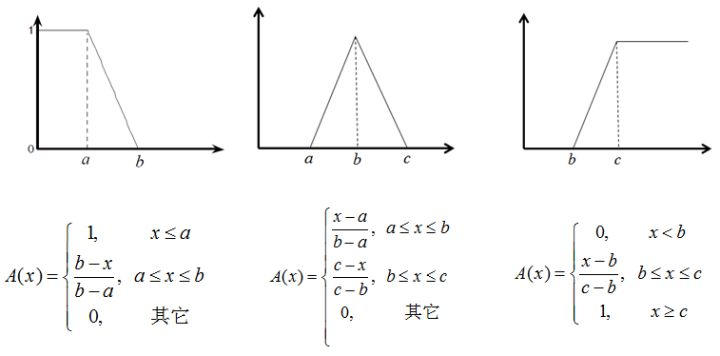
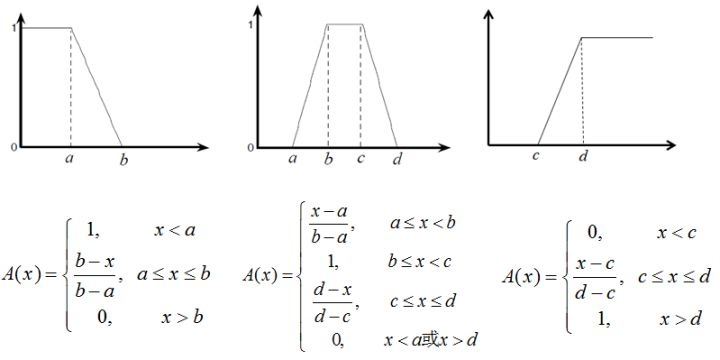
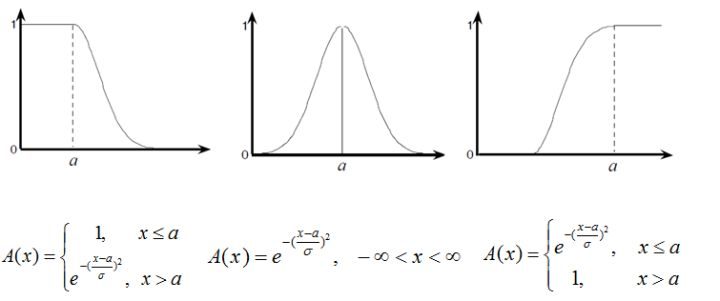
评价模型(2)
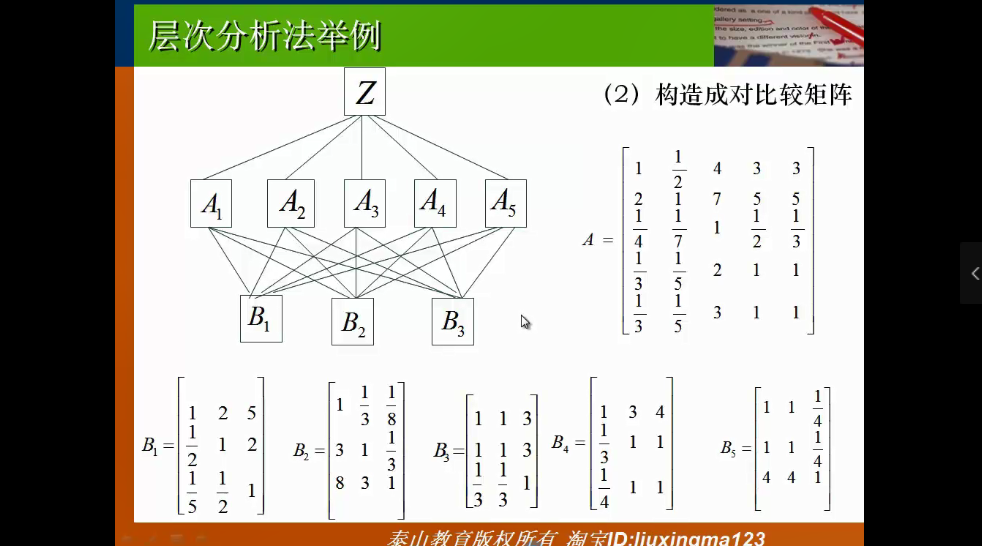
层次分析法评价(AHP)
对难以完全定量得复杂系统做出决策,主要用来求权重
第一步,建立从目标层到准则层(指标层)再到决策层(方案层)
1)最高层(目标层)——只有一个元素:决策目标;
2)中间层(准则层)——考虑的因素,决策的准则、子准则;
3)最底层(方案层)——决策时的备选方案、措施。
第二步,(最重要的一步)构造成对比较矩阵
A矩阵代表准则层各个指标之间的相互关系,B矩阵代表各个待选方案分别在5个指标中的相互比较关系。
(即若n个指标,m个决策方案,则B为(n,n)矩阵,有m个)
https://zhuanlan.zhihu.com/p/35051786

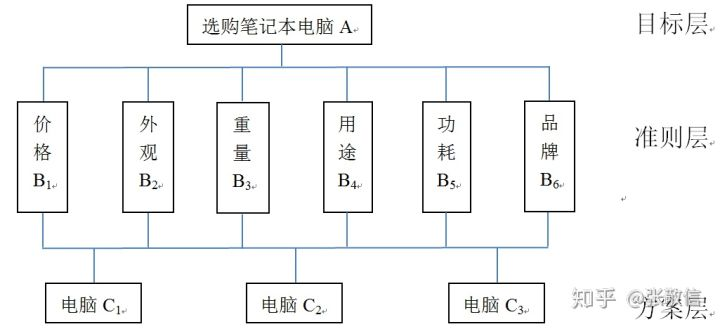
打分与权重确定
评价模型(3)
主成分分析(Principal components analysis,PCA)
找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。
- 最近重构性:样本点到这个超平面的距离足够近
- 最大可分性:样本点在这个超平面上的投影能尽可能的分开
PCA算法的主要优点有:
仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
各主成分之间正交,可消除原始数据成分间的相互影响的因素。
计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
https://zhuanlan.zhihu.com/p/32412043

主成分回归评价(principle component regression;PCR)
主成份回归可以解决变量间共线性的问题。它使用从数据抽提出的主成份进行回归,一般来说是选择前面的几个主成份。下面给出一个例子,训练集中的自变量数据X和因变量y,以及测试集中的数据Xnew和因变量Ynew,结果给出训练集中的回归模型得到的预测值和实际值的相关系数,以及测试集中相应的相关系数。
http://blog.sciencenet.cn/home.php?mod=space&uid=54276&do=blog&id=375339
主成分解释
主成分分析(PCA)是一种降维方法,通常用于通过将数量很多的变量转换为仍包含集合中大部分信息的较少变量来降低数据集的维数。
减少数据集的变量数量自然是以牺牲精度为代价的,但降维是为了简单而略微准确。因为较小的数据集更易于探索和可视化,并且使机器学习算法更容易和更快地分析数据,而无需处理无关的变量。
总而言之,PCA的概念很简单:减少数据集的维数,同时保留尽可能多的信息。
https://zhuanlan.zhihu.com/p/58663947
数据包络分析(Data Envelopment Analysis,DEA)
它是根据多项投入指标和多项产出指标,利用线性规划的方法,对具有可比性的同类型单位进行相对有效性评价的一种数量分析方法。
- 定义变量
设Ek(k=1,2,……, K)为第k个单位的效率比率,这里K代表评估单位的总数。
设uj(j=1,2,……, M)为第j种产出的系数,这里M代表所考虑的产出种类的总数。变量uj用来衡量产出价值降低一个单位所带来的相对的效率下降。
设vI(I=1,2,……,N)为第I种投入的系数,这里N代表所考虑的投入种类的综合素。变量vI用来衡量投入价值降低一个单位带来的相对的效率下降。
设Ojk为一定时期内由第k个服务单位所创造的第j种产出的观察到的单位的数量。
设Iik为一定时期内由第k个服务单位所使用的第i种投入的实际的单位的数量。 - 目标函数
目标是找出一组伴随每种产出的系数u和一组伴随每种投入的系数ν,从而给被评估的服务单位最高的可能效率。
式中,e是被评估单位的代码。 这个函数满足这样一个约束条件,当同一组投入和产出的系数(uj和vi)用于所有其他对比服务单位时,没有一个服务单位将超过100%的效率或超过1.0的比率。 - 约束条件
k=1,2,……,K
式中所有系数值都是正的且非零。
为了用标准线性规划软件求解这个有分数的线性规划,需要进行变形。要注意,目标函数和所有约束条件都是比率而不是线性函数。通过把所评估单位的投入人为地调整为总和1.0,这样等式的目标函数可以重新表述为:
满足以下约束条件:
对于个服务单位,等式(**)的约束条件可类似转化为:
k=1,2,…,K
式中 uj≥0 j=1,2,…,M vi≥0 i=1,2,…,N
关于服务单位的样本数量问题是由在分析种比较所挑选的投入和产出变量的数量所决定的。下列关系式把分析中所使用的服务单位数量K和所考虑的投入种类数N与产出种类数M联系出来,它是基于实证发现和DEA实践的经验:
https://wiki.mbalib.com/wiki/数据包络分析